
Decoding Demographics

The Best Name-Based Demographic Classifiers
Have you ever needed a data solution, then found yourself in analysis paralysis trying to weigh the trade-offs of the different options? Well this is my story of how that happened, and the guide that I used to escape this dilemma. While my case deals directly with name-based demographic classifiers, my criteria of Performance, Versatility, Accessibility, and Cost are intended to help you choose between almost any paid machine learning solution.
Key Findings on Name-Based Demographic Classifiers:
- Efficiency and Confidence: Machine learning models can efficiently extract demographic information from names with explicit confidence levels, offering a scalable complement to manual research methods.
- Top Gender Performers: Namsor with an accuracy of 87% emerges as the overall leader in gender classification. The runner up Gender API boasts a higher accuracy at 92%, if you are willing to pay.
- Top US Ethnicity Performers: Namsor is the best US ethnicity classification with an estimated 78% macro-precision, with the free alternative being ethnicolr with a macro-precision at 75%.
From 100x to Analysis Paralysis
I was tasked with determining gender and U.S. ethnicity information for approximately 100 individuals, armed with only their names and zip codes. After over 60 tedious hours searching the internet and various databases, we still lacked definitive demographic information for 30 people. For the time being, this was going to be an acceptable amount of missing information…
Then we needed to find the demographics of an additional 200 people! This was the breaking point. We were either going to spend hundreds of hours on the 'web scrawl’ approach or come up with something better. We needed a 100x solution.

With my data science background, I realized machine learning could infer demographics from individual's names or profile pictures at scale and provide confidence levels for the predictions. These confidence levels would enable a two-pronged solution - trust the algorithm's confident predictions, while manually searching for those it was uncertain about.
However, machine learning models risk perpetuating human biases about gender and race from biased training data. This concern originally made us hesistant to considering this approach. Looking into the research though, it seemed we could mitigate this problem if the models we used were trained on diverse data with few minority misclassifications.

So to even get in the door, the models needed to meet 3 basic conditions:
- Scalability: The manual search for each individual's demographic data averaged over 30 minutes per search, and sometimes still yielded no answer. We wanted a method that could quickly and consistently infer demographic information.
- Quantifiability: We wanted a method that quantified its predictions so we could know when to trust it and when to seek additional evidence. For this we needed a method that could provide explicit confidence levels for its demographic predictions.
- Equitability: Many datasets are trained on a disproportionate amount of white images or names, making them worse at predicting minorities correctly. We wanted a model that had a high accuracy or macro-precision score.
At first glance, Picture-Based Demographic Classifiers using new demographically balanced training data seemed promising with an accuracy of over 96%. Additionally, their misclassification of minorities was extremely low making it a good candidate. However, they are not considered standard in the social sciences and our team recommended using the name-based approach. Also, obtaining profile pictures for all 200 people would require ~100 hours, making this approach unscalable.
Thus, our focus shifted to the vast, and somewhat daunting, landscape of publicly accessible Name-based Demographic Classifiers. These models offered scalability, confidence levels for their predictions, claimed performance above 75%, and have a long history of being used in respectable social science. The only problem was that... there are over 20 different online name classifiers! How is anyone to choose?
I'm going to cover just that as I evaluate each tool's trade-offs, their accuracy, and which one is a good deal. But before I dive in, let's briefly explain how these name-based demographic prediction algorithms work.
What are Name-Based Demographic Classifiers?
Classifiers are a subset of machine learning algorithms trained on the relationship between input data and a specific characteristic (called a "class") in order to predict that class for new data. Name-Based Demographic Classifiers learn the connections between name components and attributes. They can then estimate the probability that a new name belongs to a particular demographic class.
But wait, why would names be useful for predicting demographics? Well, naming conventions are determined by the interplay between social and cultural values along with linguistic constraints. This makes an individual's first and last name a potential gold mine of sociocultural, linguistic, geographical, class, and other information. In fact, we map the information hidden in a person's name to categories all the time when we intuitively guess the ethnicity of someone named 'Maria Gonzalez' vs 'Justin Bieber'. However, these algorithms aren’t magic...

Specifically, the accuracy of name-based demographic classifiers suffer when minority group names are underrepresented in training data. They also struggle when naming practices significantly overlap between classes. This parallels our own difficulty classifying an unfamiliar name like "Mosakowski" as Polish or Russian. Generally, name-based classifiers perform best when supplied ample data per class, distinct naming conventions exist between classes, and names are decomposed into informative components (footnote 1). Research suggests factors like geolocation data, balanced classes, flexible algorithms, and stable intra-group naming practices may also boost performance.
Finally, Name-based Demographic Classifiers, which will from here on be called Demographic Classifiers, can be used for predicting many different attributes, but here we will focus on two main subtypes: Gender Classifiers and Ethnicity Classifiers.
Criteria for Selecting the Best Algorithm
Now that we have an overview of how these algorithms work, it's time to set out the criteria I will use to compare our options for name-based gender and US ethnicity classification. There will be four dimensions, including:
1. Performance - Accuracy/Precision: Minimizing errors and reducing misclassification amongst minorities is of prime importance. The Gender Classifiers will be judged using their accuracy score as is standard in the field.
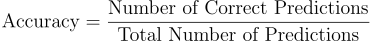
The Ethnicity Classifiers will be judged using their macro-precision score (footnote 2). Macro-precision weighs the model's ability to correctly predict each class equally, which increases the importance of misclassifying minorities or smaller classes within the data.
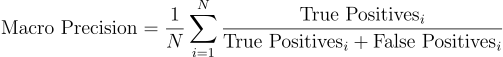
2. Versatility: A universally applicable model can handle non-English or non-standard names and even potentially use the geolocation of a name to improve predictions. Versatility will be graded out of four points, getting a point for being able to handle each of these:
- Non-latin alphabets names
- Unstructured strings
- First and last names
- Locational data
3. Accessibility: The time it takes to integrate a tool is key for users who want ready-made solutions over taking the time to develop bespoke models. The accessibility of a model will get a point for each of the following with a max of four points possible:
- Demo on website
- CSV upload option
- API access
- Open-source GitHub codebase
4. Cost: Many models offer a certain number of free name-based inferences up to a certain threshold before incurring fees. This metric will be the estimated cost of 5000 name inferences in a single month.
Finally, at the end I will give a weighted total score for each algorithm where the highest score is the overall best. Accuracy/Macro-Precision will be the most important, where the amount of the model’s score above 70% (footnote 3) will be counted as half of the final weighted score. The weighted importance of the Versatility grade will be worth 1/4, and the Accessibility grade will be 1/8. With Cost, the relatively cheapest option gets a full 1 point whereas the highest costing option gets a 0 and will be worth 1/8 of the total score. (To weigh things differently, explore the attached spreadsheet.)
Name-Based Gender Classifiers
Identifying gender from names is a well-established problem space in machine learning, partially due to its historically binary nature and highly differentiated naming conventions between the genders. However, the increasing recognition of non-binary genders suggests that these models may need to adapt to reflect a broader understanding of gender identity. Despite this evolving territory, for traditional gender classification tasks, a wide array of highly accurate and accessible models exists. Below is a table evaluating each algorithm by the four criteria above.
| Namsor | Gender API | gender-guesser | NameAPI | genderize.io | |
|---|---|---|---|---|---|
| Accuracy | 87.28% | 92.11% | 77.76% | 82.06% | 85.72% |
| Versatility | 4 / 4 | 3 / 4 | 4 / 4 | 4 / 4 | 2 / 4 |
| Accessibility | 3 / 4 | 3 / 4 | 4 / 4 | 3 / 4 | 2 / 4 |
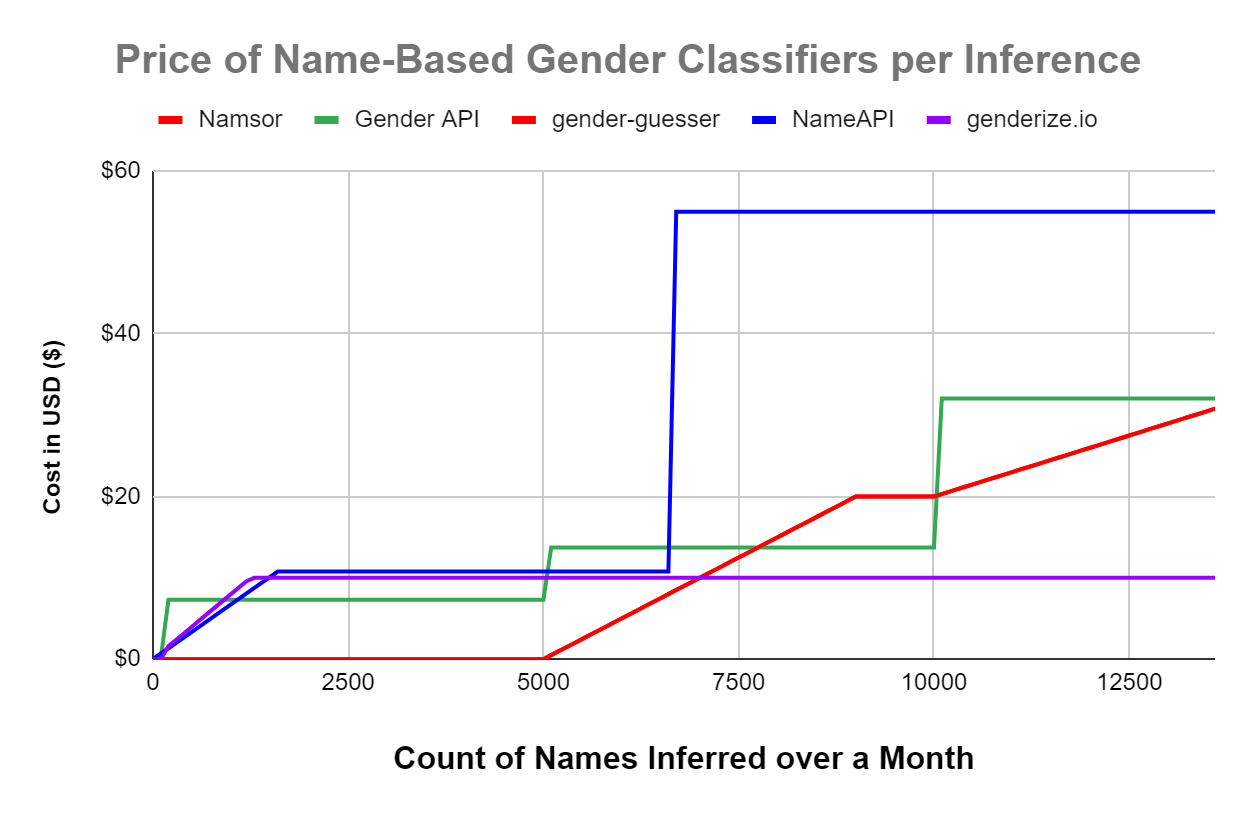
| Cost for 5000 | $0 | $7 | $0 | $11 | $10 |
- Performance - Accuracy: Gender API and Namsor have the highest accuracy with 92% and 87% respectively, although these scores are from 2018 and have likely improved. Other algorithms also scored respectably high, although they often classified names as ‘unknown’ contributing to their lower than 85% accuracy.
- Versatility: Both Gender API and genderize.io got points off because they could only handle some non-latin alphabets and neither could accept geographical data.
- Accessibility: Each model lost a point for not having an open-source library, with the exception of gender-guesser which has an old github.
- Cost: Namsor can infer the gender of 5000 names for free, whereas Gender API costs ~$7 for anything above 100 name inferences. I made a graph approximating the different pricing schemes of each tool below (footnote 4).
Name-Based US Ethnicity Classifiers
While there was a feast of Gender Classifiers, there was a famine of Ethnicity Classifiers. To be more precise, there is a famine of name-based ethnicity classifiers that predict the 4-6 US Census Bureau ethnicities. Instead, many Ethnicity Classifiers predict continental origin, nationalities, or other niche ethnic distinctions. This left us with only four viable US Ethnicity Classifiers to compare. Also, due to a lack of standard benchmarks for these classifiers, these macro-precision scores are really just directionally correct estimates (footnote 5).
It's also important to say that N2E and NamePrism have some major usage restrictions. N2E doesn't natively predict US ethnicities, and requires one to train up their own version to do so, aka a Bespoke N2E version. This option, although labor-intensive, might have superior macro-precision over ethnicolr and NamePrism. On the other hand, NamePrism's API is sometimes down, and is only usable for research, but it is a highly accurate tool if accessible.
| Namsor | ethnicolr | NamePrism | Bespoke N2E | |
|---|---|---|---|---|
| Macro-Precision | 78.0% | 75.0% | 76.2% | 78.0% |
| Versatility | 4 / 4 | 2 / 4 | 2 / 4 | 1 / 4 |
| Accessibility | 3 / 4 | 3 / 4 | 1 / 4 | 0 / 4 |
| Cost for 5000 | $130 | $0 | $0 | $0 |
- Performance - Precision: For most practical use cases you are left with Namsor, a paid web service with a macro-precision of 78%, and ethnicolr, an open source python library that has a macro-precision of 75%.
- Versatility: Between the two, Namsor is more versatile than ethnicolr due to its ability to take non-latin names and incorporate geolocation data.
- Accessibility: Namsor has an easy to use API with great documentation, but ethnicolr has an open-source github that you can easily download in the form of a python library. I'm overall pretty impressed with both options here.
- Cost: Namsor’s main drawback is that it will only predict 500 for free before charging ~5 cents per inference. This price tag might lead you to consider the notably completely free alternative ethnicolr, especially for larger datasets.
Decision Time: The Classifier for You
My final scoring spreadsheet gives half of the potential weight to Performance, 1/4 of the weight to Versatility, and splits the remaining 1/4 between Accessibility and Cost.
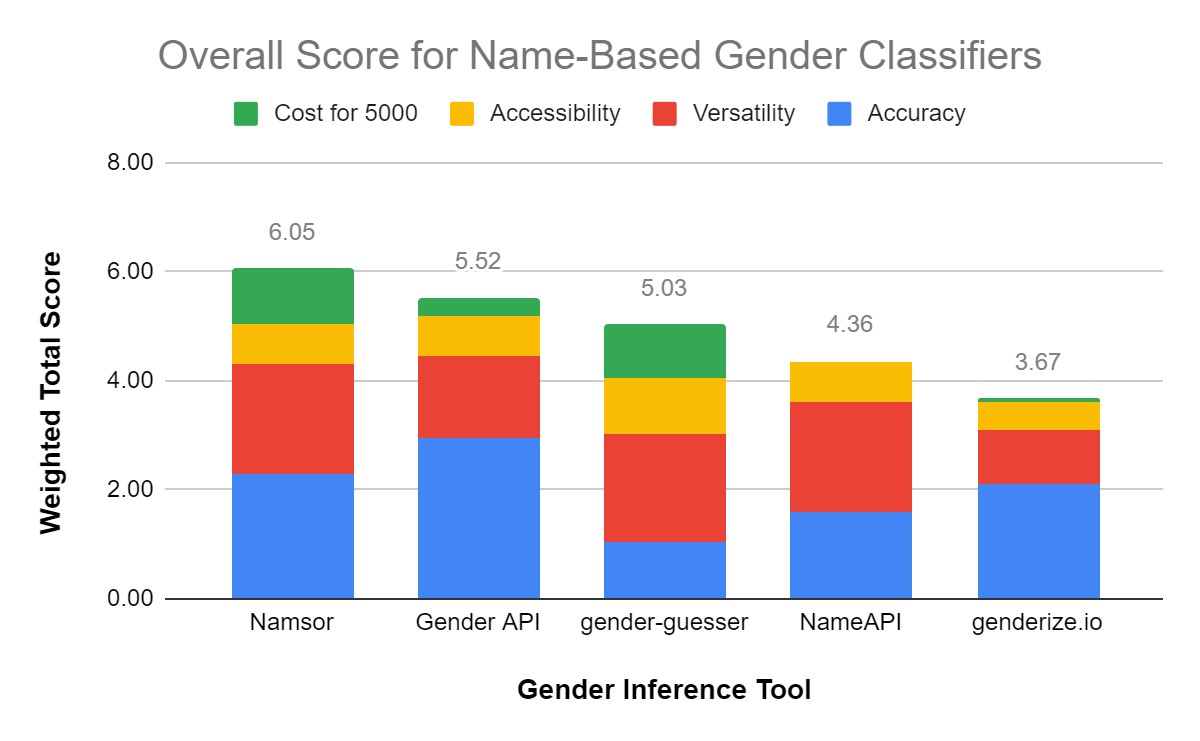
Gender Classifiers: Namsor emerges as the leader due to its high accuracy of 87.3%, good Versatility and Accessibility, and being the runaway winner in the Cost category. However, we can see that if Cost were not weighted at all, then you should consider Gender API with its outstanding accuracy of 92.1%.
US Ethnicity Classifiers: For under 500 name predictions, Namsor is the obvious solution with an estimated macro-precision of 78%. If you need something free though for many more inferences, ethnicolr is a strong second option with an score of 75%. Alternatively, if time is no obstacle, then training your own N2E classifier could be a worthwhile endeavor.

With this guide, you are now equipped to select a scalable, quantifiable, and equitable solution for inferring name-based genders or US ethnicities. However there are some other things you should consider:
- First, Do No Harm: What are the limits of Demographic Classifiers in the context of ethical considerations, ascribed vs actual ethnicity, and aggregate vs individual predictions?
- Shifting Sands of the Distribution: How accurate is your chosen classifier going to be on your specific population?
- I know how much I do not know: How confident can you be in each individual prediction and how to improve this confidence?
These questions and their solutions will be explored in the upcoming post in this series, providing actionable insights and strategies to navigate the complexities of classifier application. Additionally, a Python notebook will be shared, offering practical implementations to maximize the effectiveness of Namsor, complete with customization options to tailor the solution to your precise requirements and dataset.
Footnotes:
- One commonly used natural language processing technique in name inference is breaking a tokenized name into different n length chunks of letters called n-grams. This tends to be helpful for name inference as it allows the machine learning model to notice letter patterns, such as the three letter last names endings -yan or -ian, which commonly imply an Armenian name.
- Accuracy measures the overall correctness of a model by comparing the correct predictions to the total number of predictions made. This is the standard metric to use for evaluating gender classifiers, especially if the classes are balanced. Macro-precision calculates the average precision (the ratio of correctly predicted positive observations to the total predicted positives) across all classes, giving equal weight to each class. This is particularly useful in imbalanced datasets, ensuring that the performance of each class is equally important. Some equality evaluations also look at variance in precision between the classes, but for practical uses reducing the amount of relative false positives for each class is the most important equality metric.
- 70% was chosen as a scoring threshold because below this aggregate level of prediction performance, it seemed unreliable and potentially unethical to use the machine learning technique even as a complementary research approach.
- NameAPI and genderize.io do not have linearly increasing costs as shown in the graph, but instead enforce onerous usage limits. NameAPI allows only 30 names per minute with a 500ms delay between each request, and genderize.io allows only 100 name inferences per day. To transform this inconvenience into price, I gave each service a price slope that intersects at the halfway point for the maximum free usage possible per month.
- I couldn't find any exact macro-precision metrics tested on the same data set. ethnicolr has a 75% from this papers testing. NamePrism's score is 76.2 from its own testing, and is moderately better than ethnicolr. Namsor has a 78% from my own testing, and is moderately better than ethnicolr. And finally, N2E has a little bit better sensitivity than NamePrism, and a much better sensitivity than ethnicolr. Also N2E sensitivity performance closely matches its precision performance. Since the max score achieved so far is 78.0 and N2E seems to be better than both ethnicolr and NamePrism, albeit in sensitivity, I assigned it the best macro-precision which was Namsor's around 78%. These are obviously approximations, and might not directly apply to your use case.
{kind=link}