
Project Overview: Gender and Race Inference from Names
Project Overview: Gender and Race Inference from Names
This project provides a robust solution for converting a dataset of names in a CSV format into inferred gender and race information, with an option to include ZIP code data. It comprises a comprehensive suite of tools and Python scripts, each contributing to different stages of the data processing pipeline. From data cleaning to API calls, testing, validation, and application to CSV files, this repository is structured to handle the entire workflow efficiently. This README offers a detailed overview of the functionalities and structure of these scripts, guiding users through the process of transforming names into valuable demographic insights.
Contents Overview
1. cleaning_functions.py: A collection of Python functions designed for cleaning and preprocessing name data. It includes functions to format names correctly from various input formats.
2. api_call_function.py: Contains functions to interact with the Namsor API, facilitating the inference of gender and race based on name data. It includes parallel processing capabilities and automatic ZIP code detection.
3. testing_file.ipynb: A Jupyter Notebook dedicated to testing the functionality of the data cleaning and API call processes under various scenarios.
4. validation_for_application.ipynb: This notebook is essential for validating the entire application pipeline, ensuring data integrity and accuracy. It demonstrates the model's performance using a sample dataset.
5. apply_to_csv.ipynb: The primary interface for users, this Jupyter Notebook applies the developed functions to a user-provided CSV file containing names, outputting inferred gender and race data.
Usage Steps Overview
1. **CSV File Preparation**: Ensure your dataset is in a CSV format with columns titled 'First Name', 'Last Name', and optionally 'Middle Name' and 'zip'.
2. **Data Cleaning**: Utilize `cleaning_functions.py` to format and clean your dataset. The script can handle various name formats and include ZIP code information if available.
3. **API Inference Calls**: With `api_call_function.py`, make Namsor API calls to infer gender and race from the cleaned name data.
4. **Functionality Testing and Validation**: Use `testing_file.ipynb` for script testing and `validation_for_application.ipynb` to validate model accuracy on your data.
5. **Application to CSV**: Operate within `apply_to_csv.ipynb` to apply the entire process to your CSV file and receive a dataset enriched with inferred gender and race information.
This GitHub project offers a solution for demographic data analysis through name-based inferences, suitable for diverse applications in marketing, research, and beyond.
1. Cleaning Functions (`cleaning_functions.py`)
The `cleaning_functions.py` script is designed to clean and preprocess name data for inference. The data needs to be formatted with columns for 'First Name', 'Last Name', and optionally 'Middle Name' and 'zip' for the final inference.
- **`cleaning_type_1(df, name_set, zipcode_set)`**: This function is tailored for data where names are combined in one column, typically in the format "Last Name, First Name Middle Name". It separates these into distinct 'First Name', 'Middle Name' (optional), and 'Last Name' columns. Additionally, it can incorporate ZIP code data if provided in the `zipcode_set` parameter.
- **`extract_and_clean_names(dataframe, name_set)`**: This function serves as a customized name extractor for datasets where names might not be in a standard format. It identifies and extracts individual name components, ensuring irrelevant strings are removed. It’s particularly useful for datasets with more complex or less structured name entries.
The output from these functions ensures that the data is in the appropriate format for the subsequent API calls, with clearly delineated name components and ZIP codes.
2. API Call Functions (`api_call_function.py`)
This script interfaces with the Namsor API to infer gender and race from name data. It can handle data in parallel and automatically detects ZIP codes if available.
- **`get_namsor_gender(first_name, last_name, headers)`**: Fetches gender data from the Namsor API using first and last names. Requires API headers for authentication.
- **`get_namsor_race_geo(first_name, last_name, headers, zip_code, six_races)`**: Retrieves race/ethnicity data from the Namsor API. Can use a ZIP code for more accurate inference and supports both four and six race categories.
- **Additional Functions**: - **`process_single_row(first_name, last_name, zip_code, headers, six_races)`**: Processes a single row of data, fetching both gender and race information. This function is central to the process, combining the gender and race data fetching capabilities.
- **`infer_names(names_of_interest, headers, six_races, use_parallel)`**: This high-level function processes a DataFrame of names, invoking `process_single_row` for each entry. It can operate in parallel (using `ipyparallel`) for efficiency, especially beneficial for large datasets.
The API call functions provide a streamlined approach to fetching demographic data based on names, optionally enhanced by geographical data (ZIP codes). The parallel processing capability significantly improves the efficiency of handling large datasets.
3. Testing File (`testing_file.ipynb`)
A Jupyter Notebook designed to test the above functions. It ensures the correctness and reliability of the data cleaning and API call processes under various scenarios.
4. Validation for Application (`validation_for_application.ipynb`)
The `validation_for_application.ipynb` is a Jupyter Notebook that plays a crucial role in validating the entire application pipeline. This notebook is designed to ensure that data is processed accurately and efficiently through each stage of the pipeline, from data cleaning to API calls and final inferences.
Key Highlights of `validation_for_application.ipynb`:
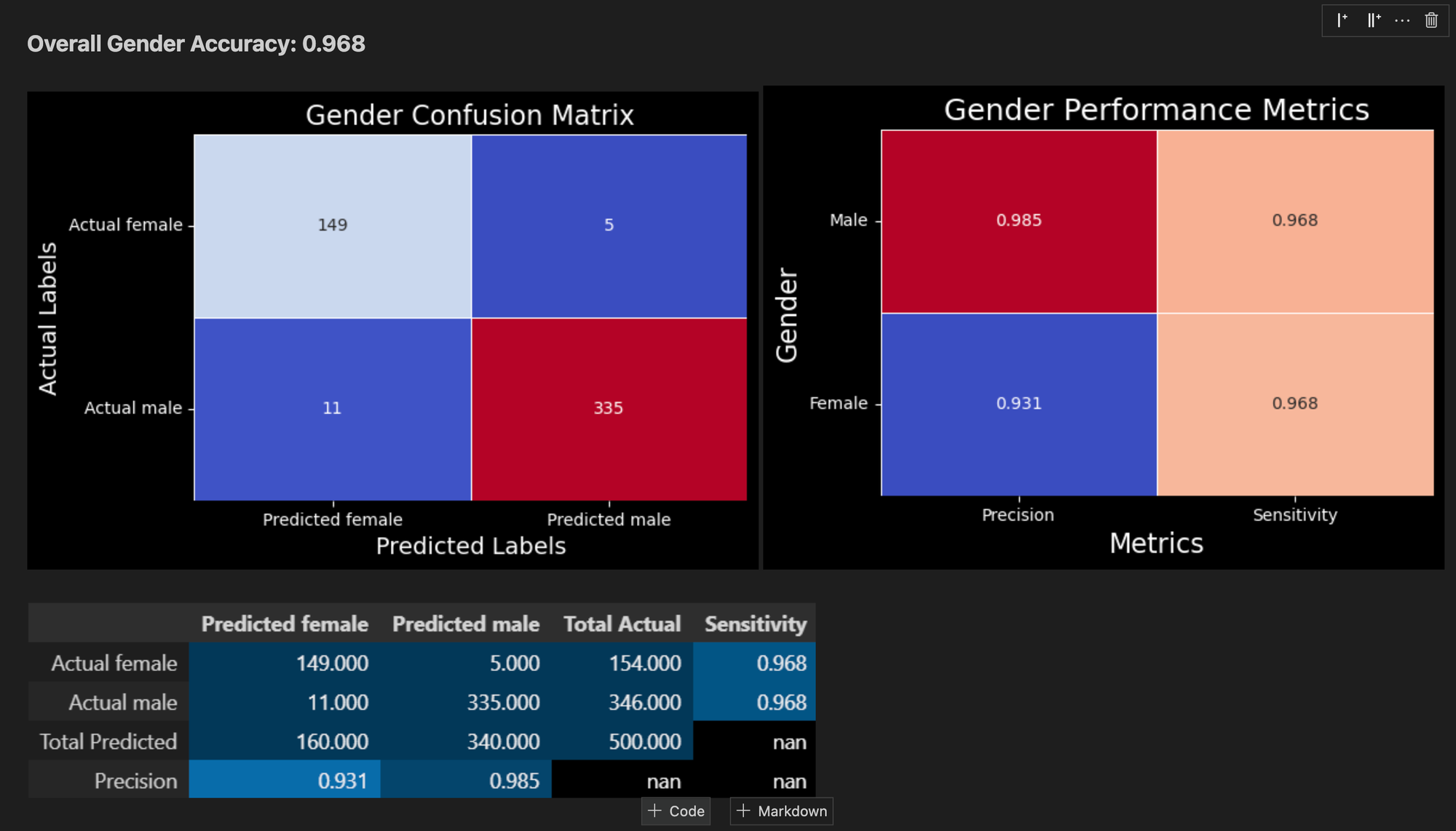
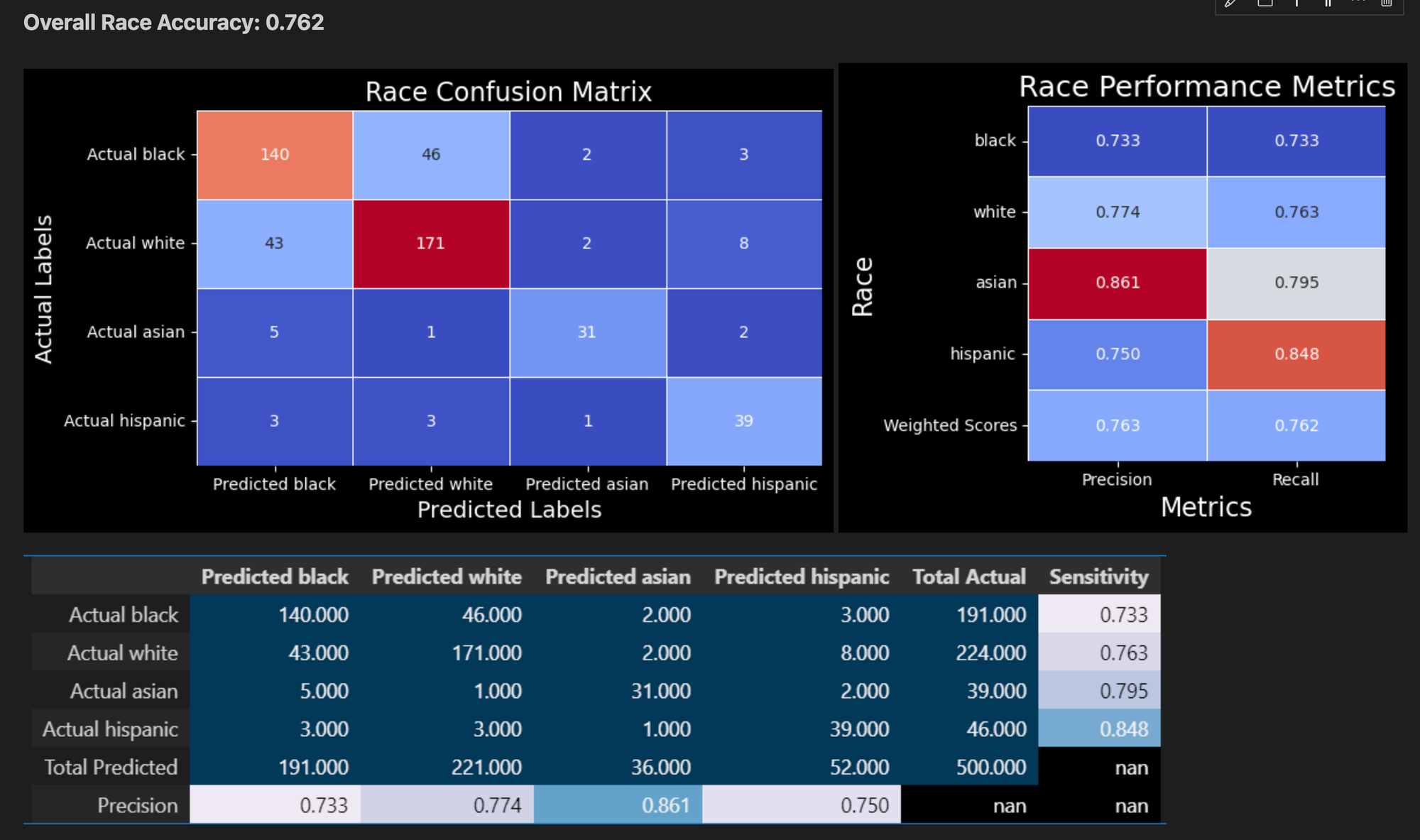
1. **Accuracy Assessment**: The notebook demonstrates the model's performance by achieving an accuracy of 76% on the Chicago names dataset. This benchmark serves as an indicator of the model's reliability and effectiveness in real-world scenarios.
2. **Sample Data Testing**: Users can input a sample from their specific dataset to evaluate how the model performs on different use cases. This feature is particularly useful for understanding the model's applicability and accuracy in diverse contexts.
5. Apply to CSV (`apply_to_csv.ipynb`)
The `apply_to_csv.ipynb` is a Jupyter Notebook that serves as the main interface for users to apply the entire suite of functions developed in this project. It is designed to take a CSV file containing names as input and output a CSV with inferred gender and race data. You will need to download the dependencies in the yaml file, and download the `cleaning_functions.py` and `api_call_function.py` scripts to run this notebook.
Key Features of `apply_to_csv.ipynb`:
**Load and Clean CSV**: Load your CSV file. If your file doesn't already have a 'First Name', 'Last Name' (and optionally 'Middle Name' and 'zip' column), you can use the `cleaning_type_1` function to clean your name data if it is all in one column.2. **Inference**: Infer gender and race from the properly formatted CSV. This will output a pandas dataframe, which you can save as a CSV file.
Future Research
All of the following are related to the improvement of the evaluation of the model's performance and accuracy on any sample data.
- Set up AUC-ROC curve evaluation of model. Might need to use percentage binning of the data to get a better idea of the model's performance and increase the number of samples to accurately evaluate each bin (reduce the variance of the successful classification rate).
- Evaluate the precision of each confidence level (i.e. how many of the samples with a confidence level of 0.8 were actually classified correctly). This will be harder for the multi-class classification model of race.
- Evaluate the performance of the 'No Zip Code' vs 'Zip Code' model. Currently the test data doesn't have ANY zipcodes. I may need to go back into the airtable base to retrieve individuals zipcodes.
- Expand Test set to include more data (currently at only 10% or 500 individuals of the total data sample which has 5000 individuals). This is limited by the amount of individuals I am allowed to request an inference for from the Namsor API, anything over 500 requests must be paid for. Might be worth a one time membership fee to get more data for testing.
- Evaluate the performance of the model with less frequent classes (native american and native hawaiian, or pacific islander) with 6 class classification model. There are almost NO 'pacific islanders' in the chicago names dataset, so it is hard to evaluate the performance of the model on this class, but still might be useful in evaluating whether we should use the 6 class classification model.
- The `Middle Name` and `Suffix` columns were dropped because the Namsor API does not support middle names or suffixes. It would be interesting to test middle names as a part of the first names or suffixes as a part of last names in later iterations of this validation project. This could potentially be done using the `full name` api call to namsor.